Sapphire Radeon X1900XT
Pag. 7 - Il chip R580
Tutto il bagaglio sino ad ora esaminato è anche alla base del Radeon X1900 che ne riprende i lineamenti fondamentali e ne accentua degli altri per meglio avvantaggiarsi nella potenza elaborativa. R580 consta di ben 384 milioni di transistor (quasi 60 milioni in più di R520), con processo produttivo a 0,09micron e, per molti versi, ha le stesse caratteristiche di R520 o Radeon X1800.
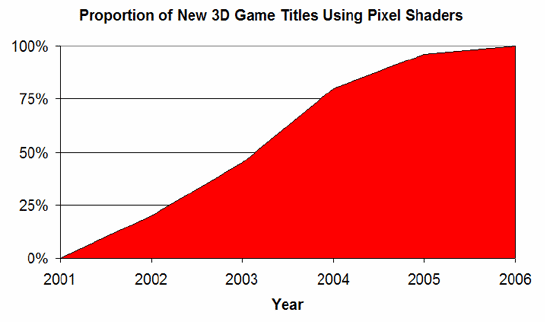
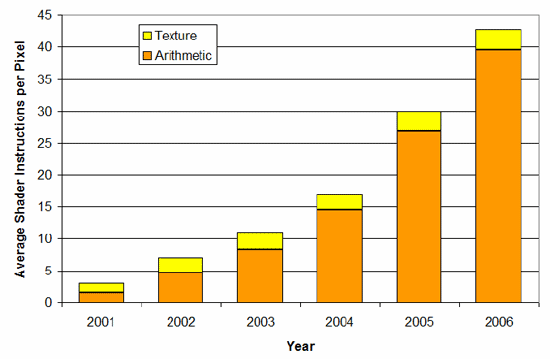
La novità di R580 è il rapporto tra il numero di unità dedicate all’elaborazione delle texture e il numero di operazioni matematiche dei pixel shader. Secondo delle statistiche diffuse dalla stessa casa canadese, sembra che il rapporto tra queste sia arrivato a 5:1, per cui ad ogni accesso alle texture il numero di operazioni aritmetiche è di 5 volte superiore, da qui la necessità di progettare un’architettura modulare che permettesse sviluppi futuri anche solo nel numero di ALU, lasciando invariate le unità di texturing. Consapevole di ciò, Ati ha deciso di incrementare il numero di Quad Pixel Shader Code (l’unità di elaborazione dei pixel shader) fino a portare tale potenza di calcolo ad un livello pari a 3 volte quello di R520, per cui tali unità sono in numero di 12 anziché 4, per un totale di 48 motori di pixel shader anziché 16.
Quello che risulta da ciò, è un’ottima potenza e flessibilità di calcolo: se R520 si fermava a 64 MADD, 64 addizioni, 64 flow-control con 16 texture fetch, R580 porta i primi 3 limiti a ben 192 mentre G71 raggiunge la stessa quota senza texture fetch oppure con 24 texture fetch raggiunge quota 96 MADD.
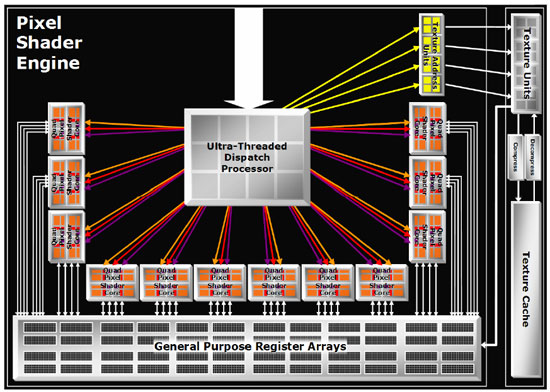
Se si pensa a quanto si sia alzata la potenza di pixel shader di questo chip grafico, possiamo anche comprendere a quanto questa possa essere limitata in alcune operazioni. Mentre con R520 si poteva ancora parlare, con la dovute limitazioni, di 16 pipeline in quanto altrettanti sono i motori di pixel shader, le ROP e le TMU, adesso con 48 PSU è possibile anche andare in casi in cui il collo di bottiglia diventino le ROP (ammesso che il rapporto tra PSU e TMU di cui parla Ati continui a valere nell’applicativo sotto test).
Anche le TMU hanno subito un’importante implementazione denominata FETCH4 al fine di migliorare la velocità di rendering e la resa di tutte le texture con valori a singola componente (come le ombre morbide). Con questa tecnica si vanno a realizzare 4 fetch di tipo point sample in 4 indirizzi adiacenti delle shadow map per ciclo di clock. Il rapporto di velocità è, in questo modo, di 4:1 rispetto al passato.
Inoltre è stata incrementata del 50% la quantità di cache disponibile al motore Hiechical-Z per la rimozione delle superfici nascoste (miglioramento velocistico alle alte risoluzioni).
Infine migliorata la gestione dinamica delle frequenze al fine di rendere più reattivo il core nei confronti di un eventuale carico elaborativo e sono stati anche incrementati i registri generali.
Come per tutta la famiglia X1K, anche il Radeon X1900 è dotato della tecnologia di gestione dinamica del voltaggio della GPU in modo non solo da risparmiare corrente preziosa in fase di mancato uso dei motori di rendering, ma anche di tenere basso il dispendio di calore prodotto. In questo modo la GPU è pienamente alimentata solo in corrispondenza di un elevato carico di lavoro su una scena 3D. I consumi, nonostante il buon bagaglio tecnico supplemementare di X1900 rispetto a X1800, sono cresciuti di poco: mentre X1800 consuma 110W circa, x1900 ne assorbe 120W.

