Sapphire Radeon X1900XT
Pag. 4 - Caratteristiche (2)
Per rendere più fluido e meno soggetto a latenze interne il lavoro dei motori indipendenti di pixel shader, i Quad Pixel Shader Core si appoggiano su una cache veloce e condivisa denominata General Purpose Register Array: in questo modo si va a completare l’idea di efficienza di cui prima in quanto una unità di calcolo non deve necessariamente completare il lavoro di elaborazione del colore su un unico pixel, ma può anche solo generarlo in maniera parziale e lasciare ad un’altra unità il completamento dell’elaborazione, da qui l’estremo parallelismo del nuovo concetto di elaborazione di Ati. Per fare un esempio, si pensi ad un applicativo che si scopre più efficiente distribuendo il lavoro parziale di rendering in parallelo sulle unità di pixel shader: basta una programmazione software del driver in modo da indirizzare l’Ultra-Threading Dispatch Processor a gestire il carico di lavoro nella maniera più conveniente: un certo tipo di dati verrà inviato su parte dei motori di pixel shader, gli altri prenderanno il lavoro parziale di questi e continueranno il lavoro di rendering per generare la scena finale, un po’ come fa lo SLI di nVidia che a seconda dell’applicativo sceglie la modalità di rendering più congeniale al raggiungimento delle prestazioni massime. Si comprende bene come questa tecnologia si sposa in maniera ottimale con le richieste di cicli, ramificazioni e sotto-routine dello SM3.0 potendo gestire un numero infinito di shader.
Nel dettaglio le unità di pixel shader sono dotate di 2 ALU, come G70 di nVidia, ma con Ati in vantaggio per via della possibilità di eseguire 2 operazioni di pixel shading e una texture fetch in contemporanea (per nVidia o solo le prime 2, oppure una di ciascuna delle 2 categorie).
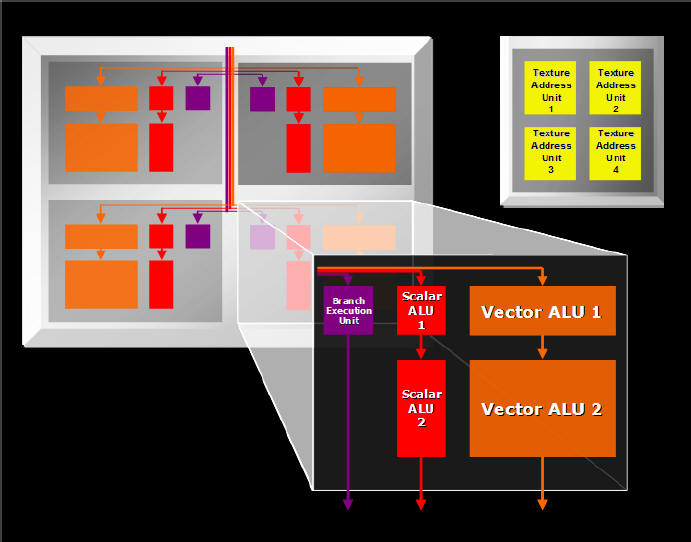
Per ciascun ciclo di clock, le 2 Alu generano 8 operazioni di addizione, (per ogni ALU, un vettore di tre elementi ed uno scalare) oppure quattro addizioni e quattro moltiplicazioni, oppure quattro addizioni e quattro MADD (un’operazione combinata di addizione e moltiplicazione). A questo si aggiunge un’istruzione di controllo del flusso ed una texture fetch.
Ricordiamo che G70 di nVidia permette, senza texture fetch, di eseguire otto operazioni di tipo MADD (contro quattro MADD e quattro addizioni di R520), mentre con texture fetch R520 è sempre in grado di eseguire un maggior numero di operazioni in quanto può sempre sfruttare le due ALU disponibili in ogni unità di pixel shading.
Sono 2 approcci diversi che non trovano né vinti né vincitori in quanto la loro maggiore velocità dipende dal tipo di shader da elaborare che andrà a favorire ora l’una ora l’altra applicazione.
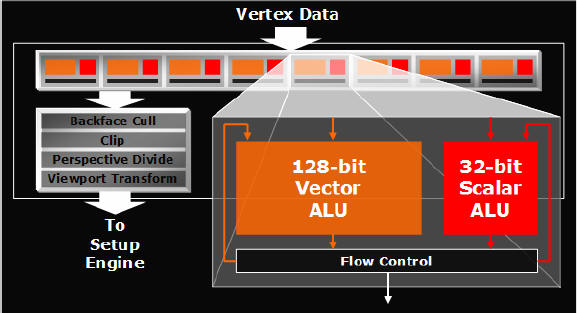
Come nVidia, anche Ati ha deciso di rendere più veloci le unità di elaborazione dei vertici capaci di raggiungere 2 istruzioni per ciclo di clock e, assieme a quelle di pixel shader, si migliorano nella precisione per componente, ora fino a 32 bit (per un totale di 128bit) invece che a 24bit. Anche in questo sta il pieno supporto dello Shader Model 3.0 da parte dei nuovi chip video.
La precisione a 128bit è mantenuta lungo tutto il percorso di rendering, per cui la qualità dell'immagine non subisce mai alterazioni a seguito di processi di arrotondamento o approssimazione. A parte la qualità in fase di illuminazione della scena (vedi HDR più avanti), le tecniche di utilizzo delle texture per il disegno dei poligoni (come il Displacement Mapping) possono quindi contare su una mappa base più fedele, per cui il risultato finale sarà di gran lunga migliore di quello consueto. Questo, inoltre, apre anche le porte a soluzioni di sostegno della GPU ad operazioni intensive fino a poco tempo fà di sola responsabilità della CPU e rende più realista l'orizzonte del calcolo in parallelo dei 2 centri di lavoro del PC: CPU e GPU che insieme concorrono al risultato finale di una elaborazione dati molto gravosa.

