LEZIONE #5: VISIONE DI INSIEMEAllora spero la prof non sia iscritta ad amdplanet perchè inserisco una immagine del suo libro:
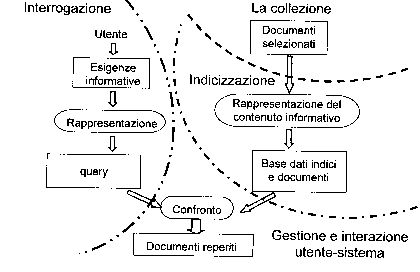
- Schema del processo di reperimento dell'informazione
- 0006.jpeg (26.45 KIB) Osservato 25432 volte
scusate la qualità ma così resta leggera.
Quello che vedete sopra è per l'appunto lo schema di un sistema di reperimento, in questo modo possiamo riassumere quanto detto sinora: come vedete e come detto in precedenza tra utente (a sinistra) e sistema (a destra) la struttura è simmetrica, infatti questo schema viene detto "ad U".
A sinistra vediamo un utente che presenta una esigenza informativa, ovvero vuole ricercare qualcosa all'interno di una collezione di documenti che si trovano dall'altro lato della figura. Attraverso l'ormai noto processo di indicizzazione viene prodotto un indice che rappresenta il contenuto informativo di tutta la collezione (bene o male, questo dipende da come viene fatta l'indicizzazione): come sappiamo il risultato è una serie di termini (descrittori) collegate mediante una struttura dati ai documenti che li contengono.
Dall'altra parte abbiamo il processo simmetrico che agisce sulla stringa di testo inserita dall'utente: viene analizzata e su di essa si ricavano altri descrittori; a questo punto rimane da fare il confronto tra i descrittori presenti nell'indice della collezione e quelli ricavati dall'interrogazione dell'utente, se ne vengono trovati di uguali, il sistema reperisce i documenti ad essi associati e li restituisce all'utente.
Altra immagine di bassa qualità
![[bigsmile]](./images/smilies/snork_lach.gif "weint_vor_lachen")
:
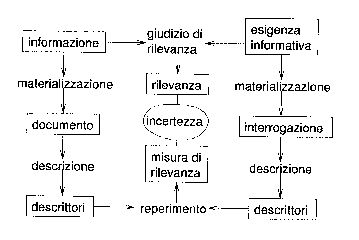
- Elementi e processi del reperimento dell'informazione
- 0007.jpeg (18.75 KIB) Osservato 25431 volte
dovete fare un piccolo sforzo perchè in questa immagine che come al solito presenta una simmetria, l'utente sta a destra e il server a sinistra, a differenza di quella precedente dove avveniva il contrario.
Prima di spiegare in breve cosa significhi quella roba vi dico due tre cosette: con
materializzazione si intende il processo per il quale l'informazione (contenuta poi nei documenti della collezione) e l'esigenza informativa (dell'utente) sono espresse rispettivamente in documenti ed interrogazioni. Niente paura tutto al solito molto semplice: da una parte, al server, abbiamo una certa quantità di informazione che deve essere posta in "formato documento", ad esempio se il sistema è automatico i documenti dovranno essere in forma digitale. In sostanza il sistema deve essere ovviamente in grado di reperire questa informazione e il pc che legge la carta non mi pare molto comodo. Dall'altra parte abbiamo il povero utente che ha una esigenza informativa: bene la materializzazone in sto caso è il processo che lo stesso utente fa per convertire la sua esigenza che si trova nella sua mente in una interrogazione al sistema. Dovrebbe essere chiaro, come vedete il risultato della materializzazione è un documento da una parte (elaborabile dal pc) e una interrogazione dall'altra (anch'essa necessaria perchè il pc non può certo elaborare la mente dell'utente).
Dai documenti come sappiamo ricaviamo i descrittori, così come dall'interrogazione dell'utente e questi dovranno essere confrontati al fine di reperire i documenti più rilevanti.
La roba al centro: come già detto qualche tempo fa è impossibile stabilire con precisione assoluta per un sistema automatico la reale rilevanza dei documenti restituiti per l'utente, proprio perchè non possiamo entrare nella sua testa e perchè la rilevanza dei documenti cambia nel tempo, un utente può giudicare a mezzogiorno rilevante una cosa e alle 15 no, questo perchè in quelle tre ore probabilmente ha migliorato le sue conoscenze, e il documento non gli porta alcuna informazione in più, cosa che poteva avvenire a mezzogiorno. Quindi in sostanza la rilevanza non è facile da trovare, ma si trova, con una certa incertezza, altrimenti saremmo messi molto male.
 ).
).
 copione
copione